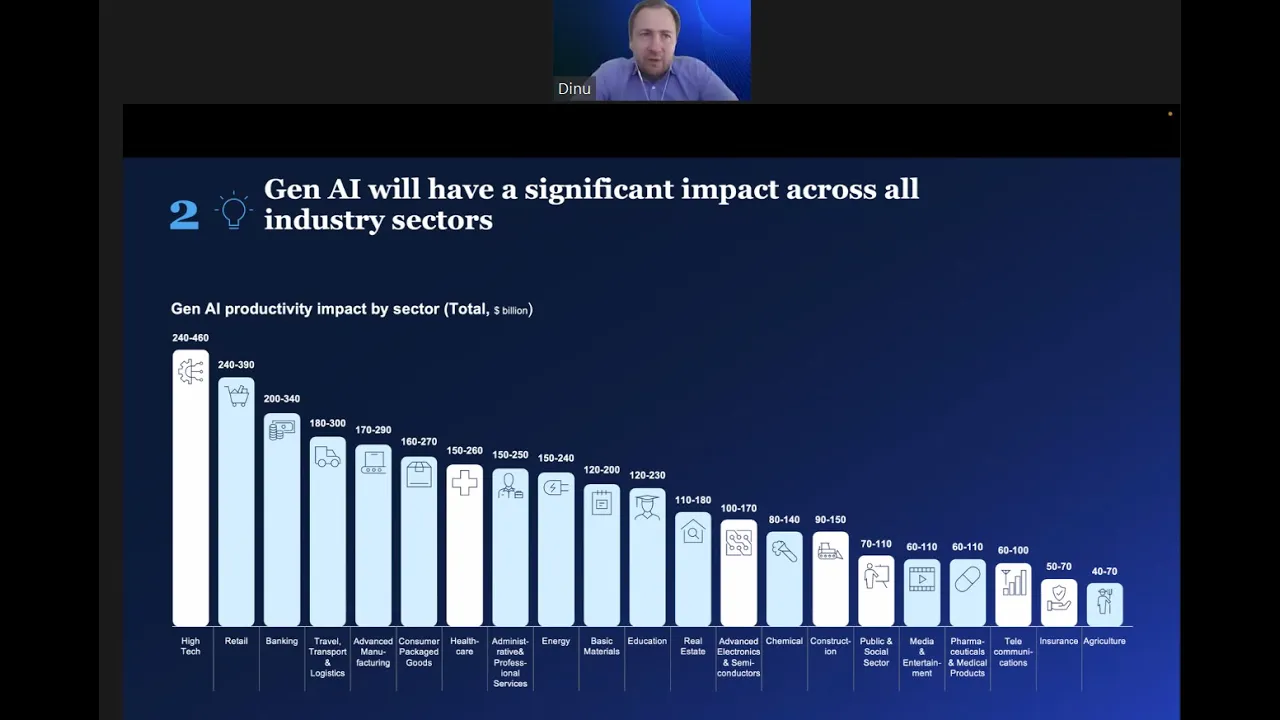
Build ML and Gen AI for Production

MLRun Architecture
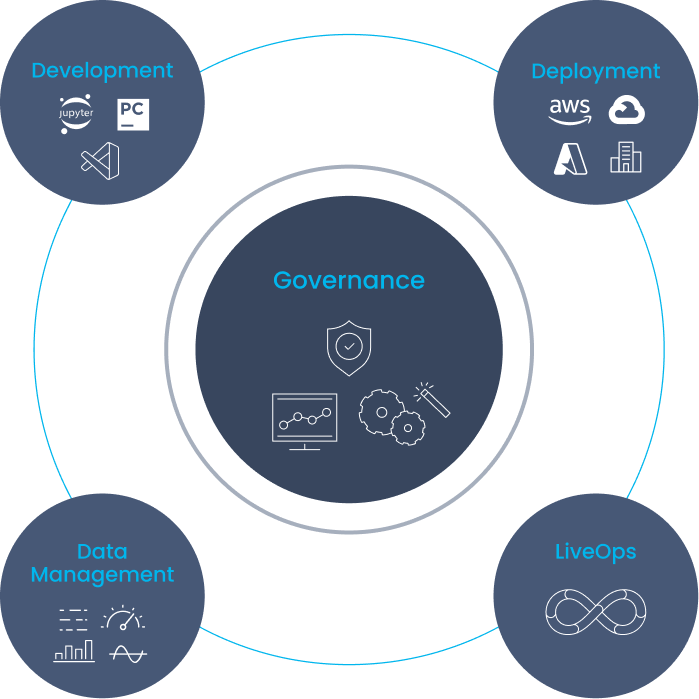
Accelerate and Streamline AI with MLRun

Faster time to production
Automated productization
Automate your AI pipeline end to end – From training and testing to deployment and management in production. Rapidly deploy real-time serving and application pipelines. Automate model training and testing pipelines with CI/CD. Auto-generate batch and real-time data pipelines. Reduce engineering efforts, deliver more projects with the same resources and increase robustness and availability.

Reduction in computation costs
Scale and elasticity
Orchestrate distributed data processing, model training, LLM customization and serving with auto-scaling and high-performance architecture. Allocate VMs or containers on demand. Provision GPUs to improve utilization. Optimize resource use to reduce compute costs and seamlessly scale workloads as needed.

Collaboration
Collaboration
One technology stack for data engineers, data scientists and machine learning engineers. Break down silos, drive re-use and sharing between roles, and reduce maintenance times.

End-to-end observability
Responsible AI with minimal engineering
Auto-track data, lineage, experiments and models. Monitor models, resources and data in real time. Auto-trigger alerts, re-training and LLM customization. Enable high quality governance and reproducibility.
Open architecture
Future proof your AI applications
Future-proof your stack with an open architecture that supports all mainstream frameworks, managed ML services and LLMs and integrates with any third-party service. Deploy your workloads anywhere – multi-cloud, on-prem or in hybrid environments.
Application Examples
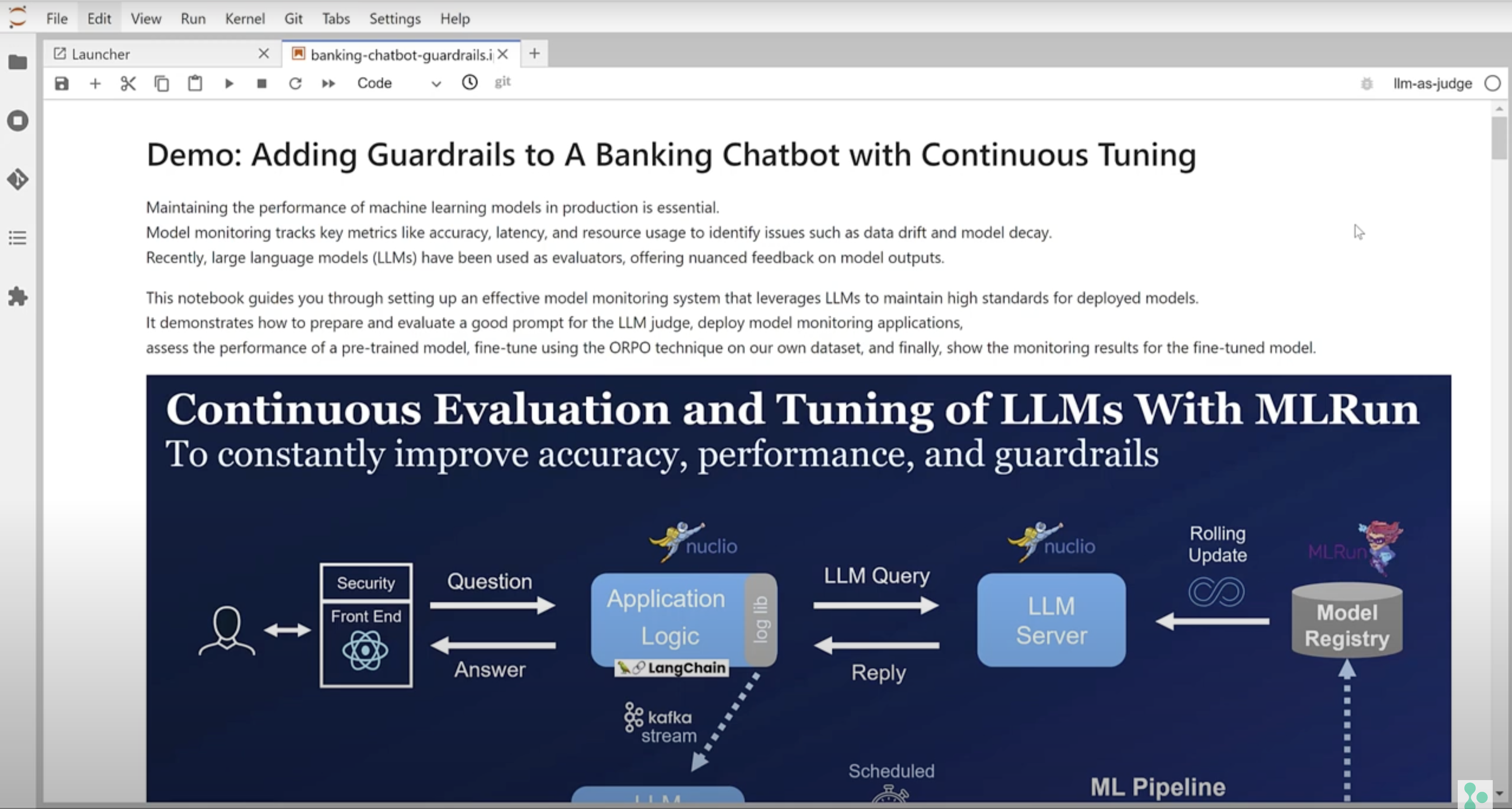
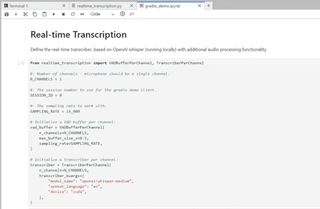
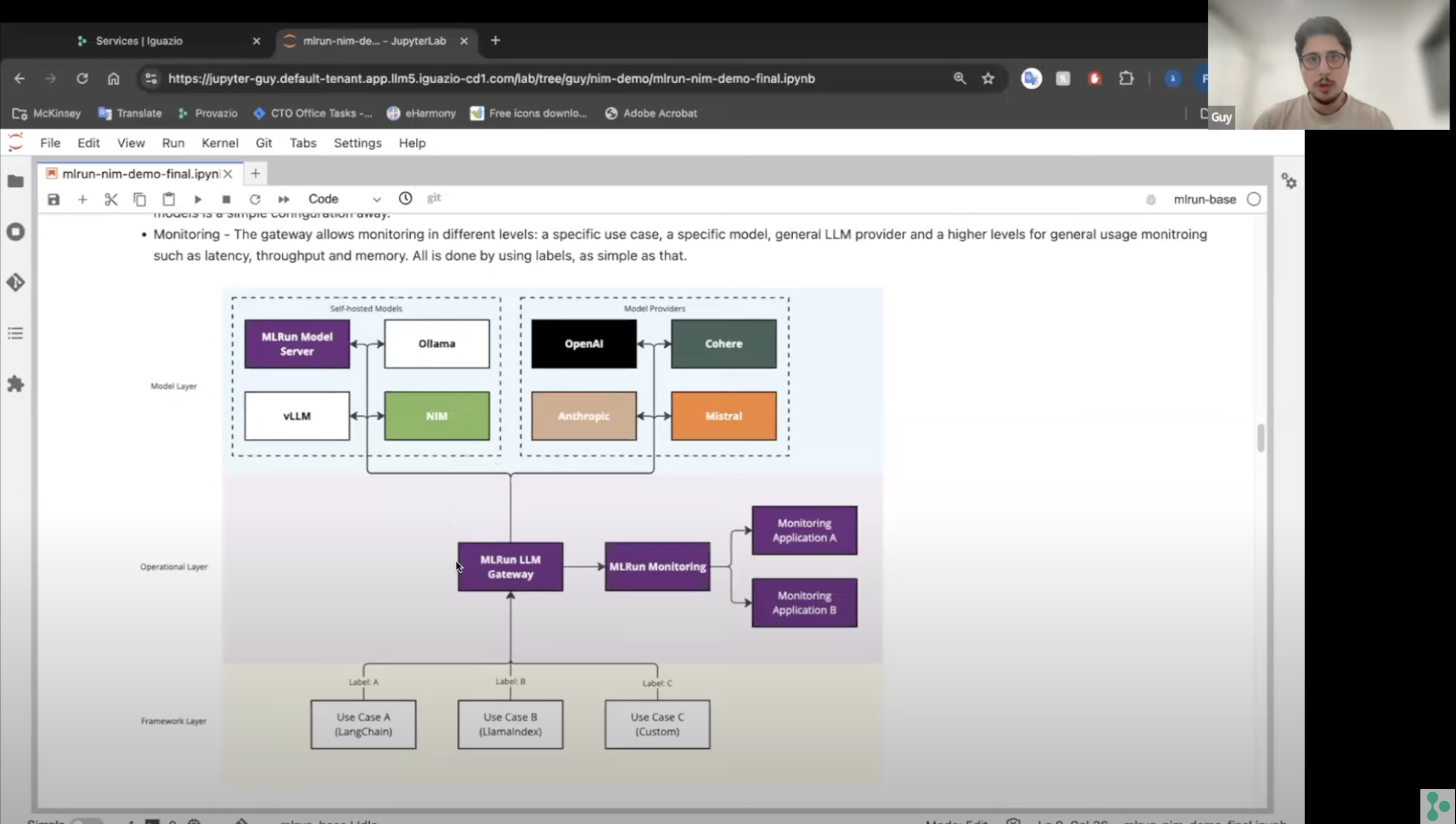
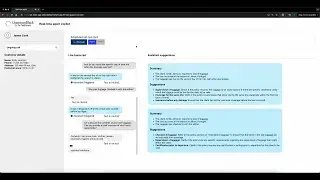
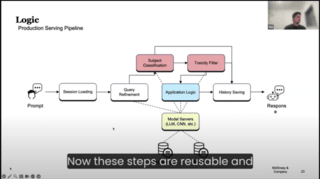
Start Using MLRun Now
Built-in Integrations